
Make Your Database Disposable!
Marvin and Stanley work for different companies that do the same thing. Both businesses deliver a stream of relevant content from the web to their customers. To do this, they both begin by filtering content based on keywords. All content is stored in MySQL, and the content is matched to the appropriate customers. This is simple and effective.
Marvin comes from an enterprise background, and his architecture is to shuttle all incoming data straight into the MySQL database. His looks like this:
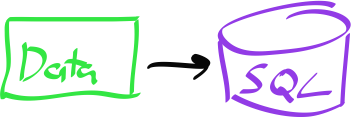
Stanley, on the other hand, has worked in data collection before and wants to try out Kafka, a log-like queue-like system. His architecture has all data coming into Kafka first, and a thin process to shuttle the data from Kafka into MySQL. Importantly, this importer will perform an upsert (Insert OR Update). This means the same data can be run through the importer without corrupting the database. His looks like this:

Running out of disk space
Business is great for both companies, and soon they are pulling in lots of data. Disk space is beginning to run out. Marvin and Stanley come to the same conclusion: the massive amount of text should not be in MySQL. Instead, MongoDB is a good solution with its ability to shard.
In addition to updating code to write to the new database, Marvin has to write migration scripts and tools to ensure data makes its way out of MySQL into Mongo. Not only is this tedious and time-consuming, but it is also throwaway. In addition, there is no longer a single data authority.
Stanley, on the other hand, writes a new importer for Mongo (which will be used for all data, new and old) and simple runs the existing data.
New Features
Business is great for both companies, and soon they want to add value by delivering topics for each document.
Marvin has to build code to handle new data, as well as code to backfill existing data. Stanley, on the other hand, updates the importer to process topics and simply runs the existing data.
We need search
Business is great for both companies, and soon they want to add advanced search capabilities. Marvin and Stanley both know that neither MySQL or Mongo are the best choice. They both know that ElasticSearch can replace Mongo and provide superior text searching. To complicate matters, management doesn’t trust the new technology and wants ElasticSearch running side by side with Mongo until it can be proven.
Once again, Marvin must build migration code that will be thrown away. Even more troublesome is making sure to keep the data routing to both databases and stay in sync. Once the new index has proven itself, the code must be changed to eliminate the Mongo writes.
Stanley, on the other hand, writes a new importer for ElasticSearch. After running the existing data, the importers for Mongo and ElasticSearch both listen to the same incoming Kafka topic. Once the new index has proven itself, the Mongo importer is simple stopped.
Stand up a test environment
Business is great for both companies, and soon they want to harden their quality assurance. Rather than test again the production environment, they would both like a new environment with the last month’s worth of data.
Marvin must build scripts to export data from production and then insert it into a new database. Stanley, on the other hand, stands up new importers pointing to the new databases and plays the last months worth of data from the Kafka topic.
Lessons Learned
Systems that are built on data are always evolving.
- The quantity of data is ever-growing
- The analysis and value add is ever-changing
- Thee performance is always trending down as the mass increases
To address these challenges, the system must evolve over time and do so from a solid base. Sometimes changing the database will get you to the next level. Sometimes it may take multiple database technologies to get to the next level. If you are used to using the database as your store of record, this will give you the heebie-jeebies because of data migrations and data integrity across stores.
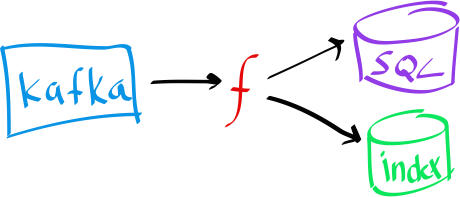
Instead, consider today’s system a function over the data. The output of the function is your database. To change the system, change the function.